Do Large Language Models Understand High-Level Message Sequence Charts?
This static website organises the experimental artefacts accompanying the supplied paper. It links the original data and adds uniformly styled HTML renderings of every Word document in the package.
Problem statement and experimental overview
The paper studies whether contemporary Large Language Models can produce outputs that are consistent with the formal semantics of Message Sequence Charts and High-Level Message Sequence Charts. The experiments focus on semantic concepts including event identification, causal ordering, abstraction, composition, traces, and labelled transition systems.
The benchmark uses nine MSC/HMSC subject systems. Natural-language prompts were submitted to three LLMs: Gemini 3 - Thinking, GPT-5.4 - Thinking Deep, and Qwen 3.6 Plus - Thinking. The resulting answers were judged against reference solutions and aggregated by task type, example, and model.
Contents and steps
Converted Word documents
59 Word files have been rendered as HTML pages using a shared stylesheet. Each converted page links back to the original Word file, which is included unchanged under data/.
To preserve the original evidence, the contents of the Word documents have not been edited. Site navigation and surrounding explanatory text use British English.
Summary of results reported in the paper
| Task area | Reported outcome |
|---|---|
| Basic MSC semantics | Strongest performance, with 87.9% combined accuracy on event identification and event ordering. |
| Semantic transformations | Weak overall performance, especially abstraction, with 36.1% combined accuracy across abstraction and composition. |
| Behavioural semantics | Moderate trace reasoning but poor LTS reasoning, with 41.7% combined accuracy. |
| Recurring pain patterns | Abstraction, LTS reasoning, and difficult composition cases. |
Subject-system images
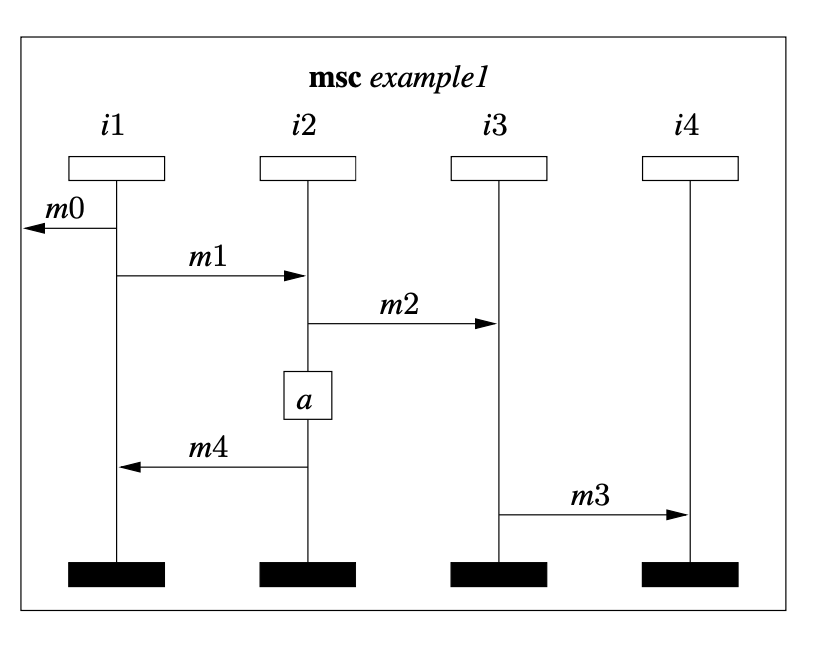
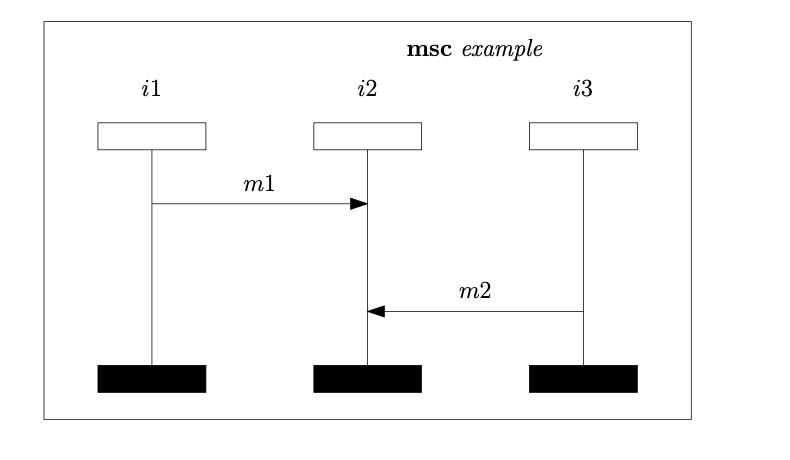
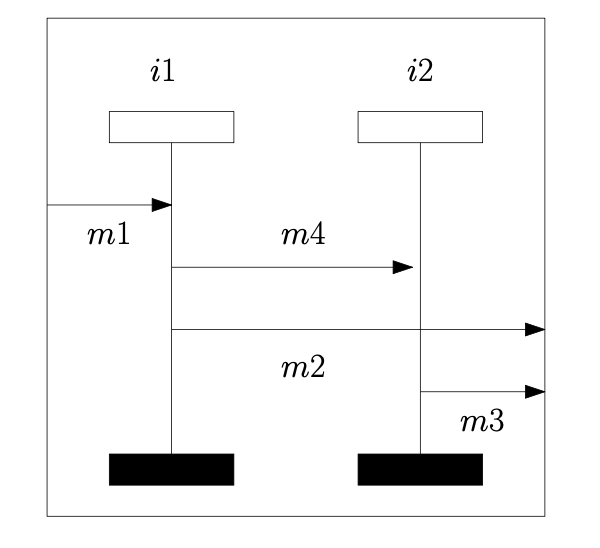
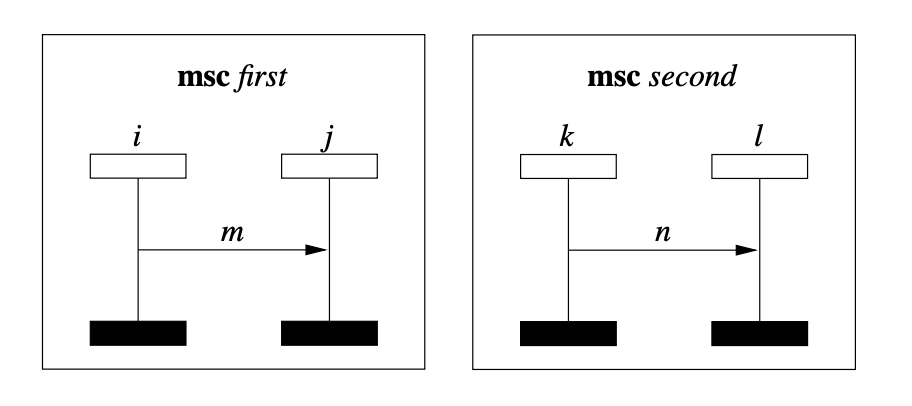
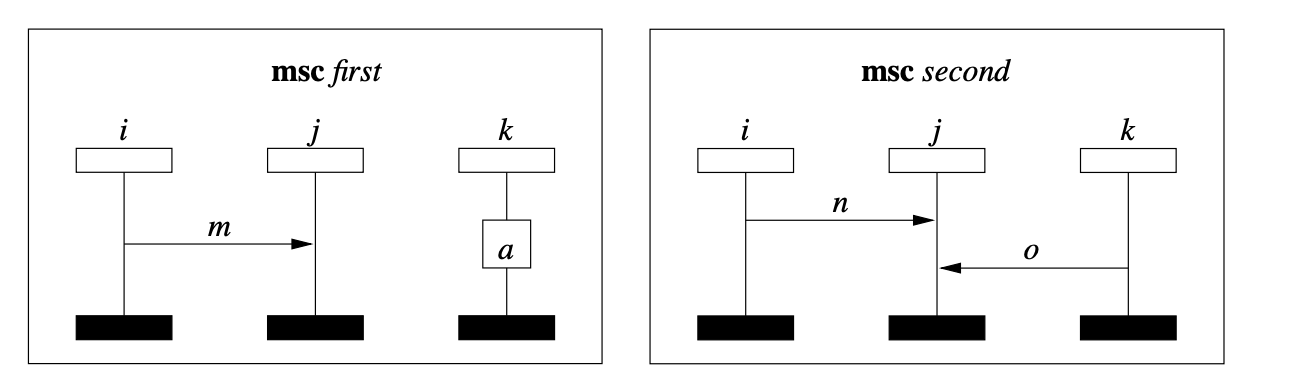
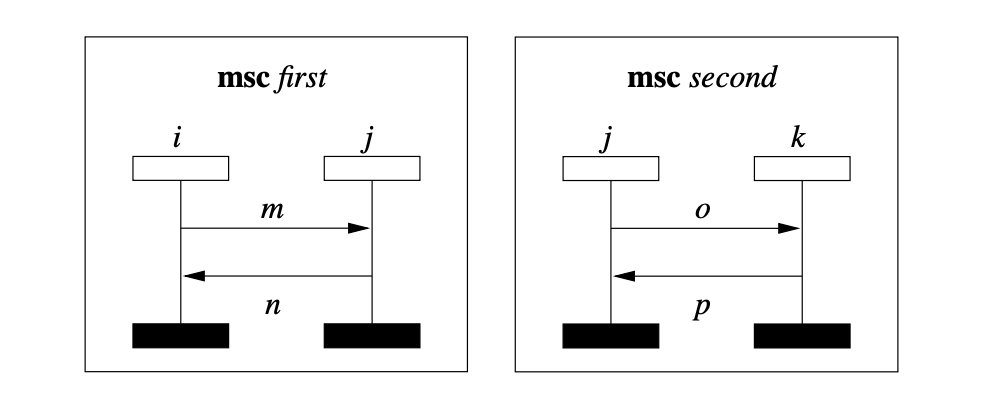
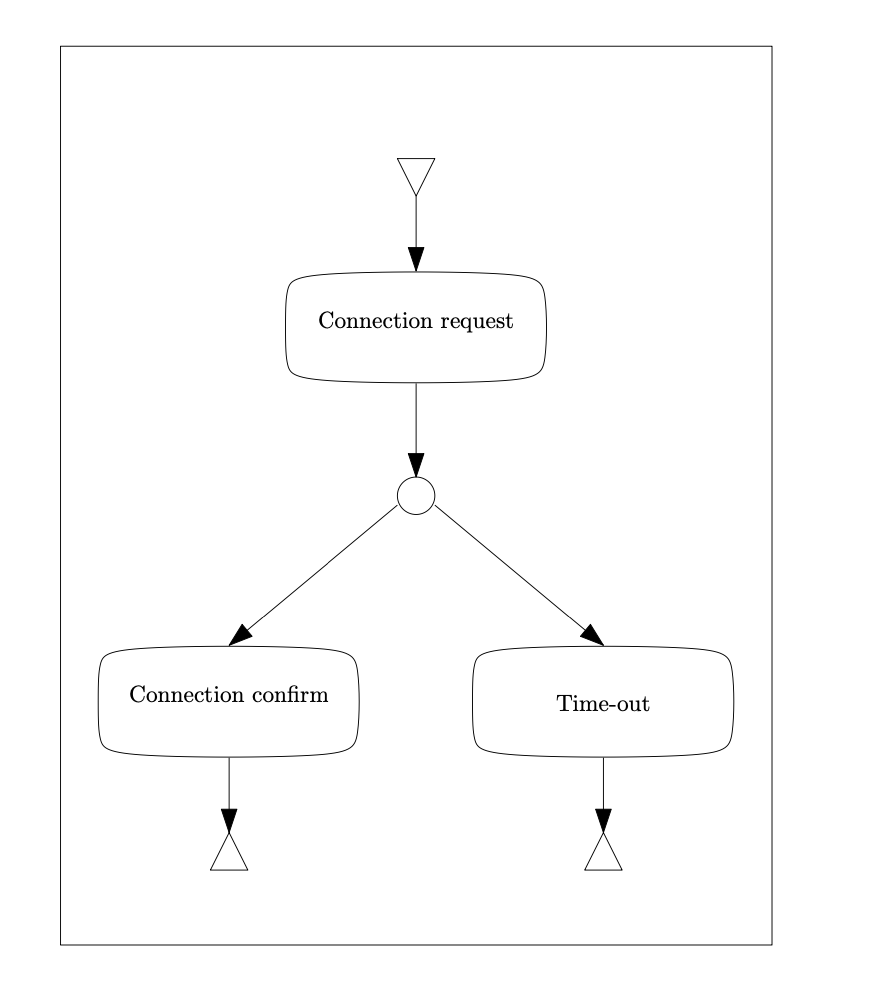
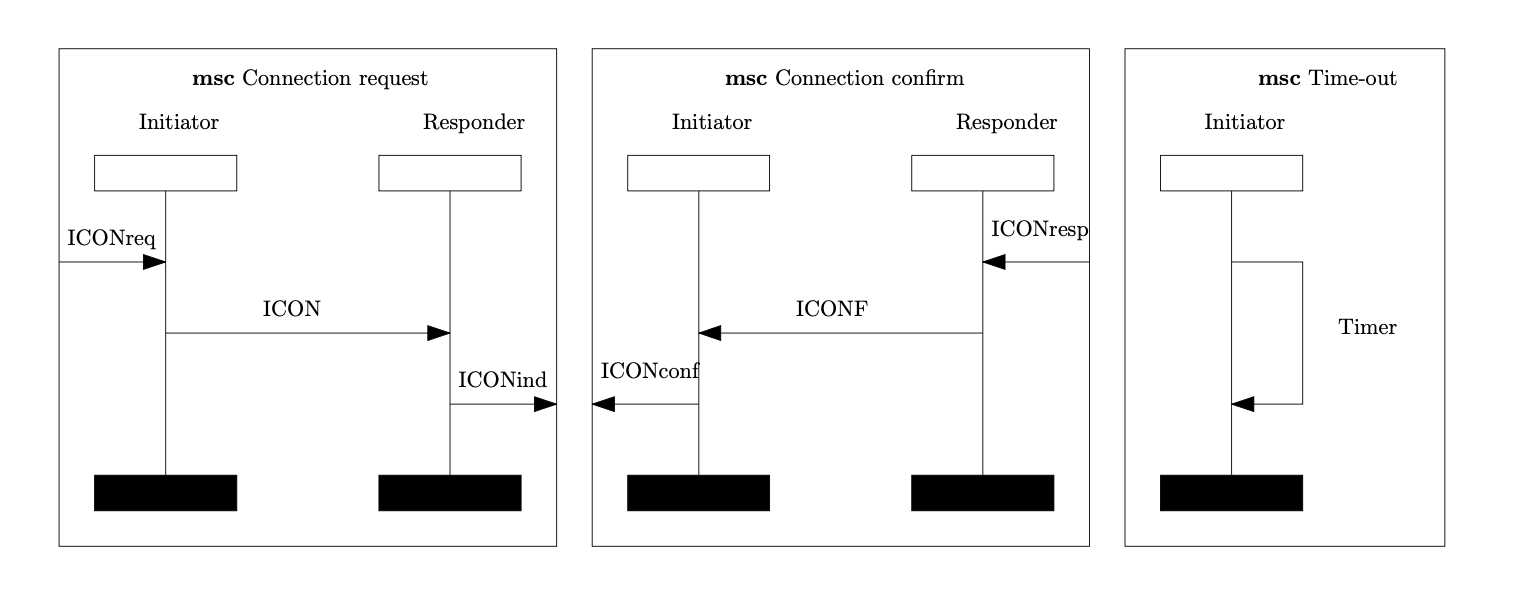
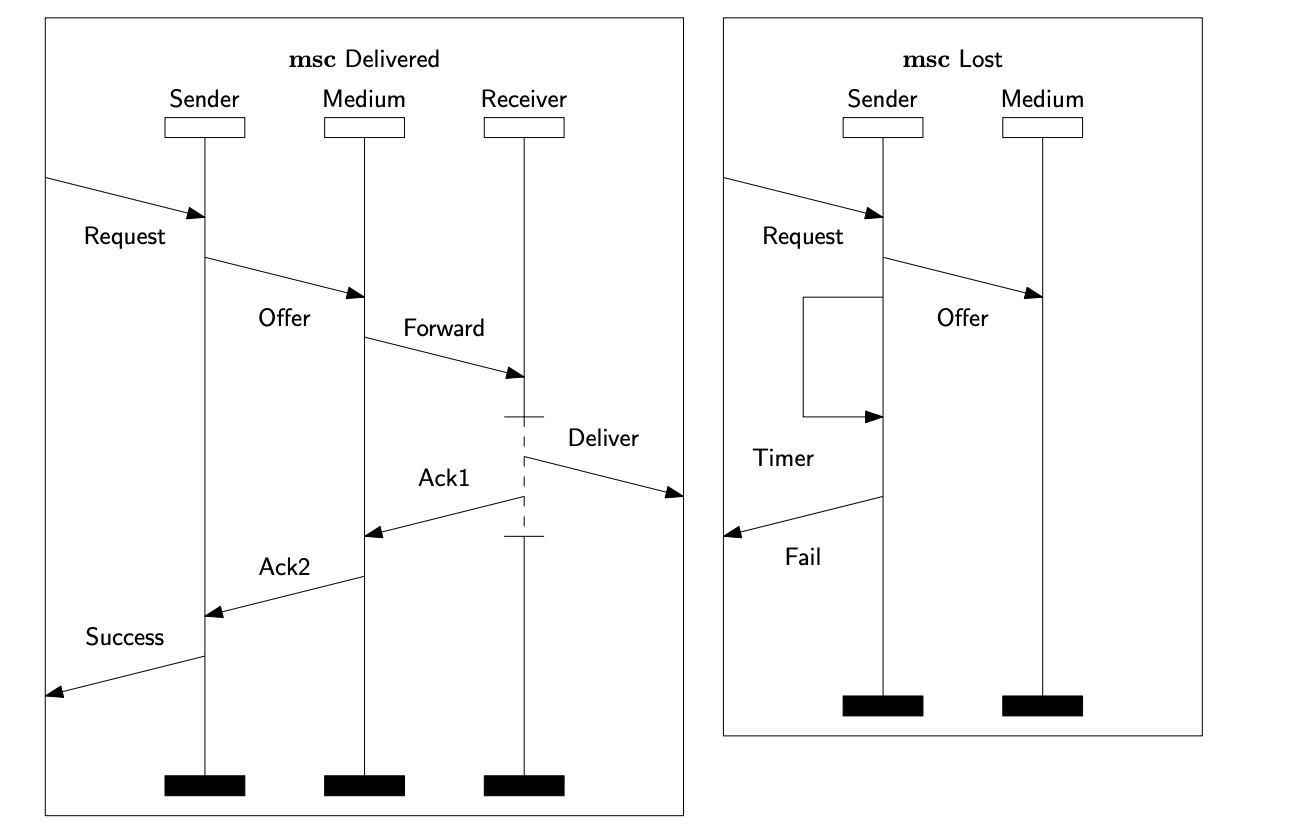
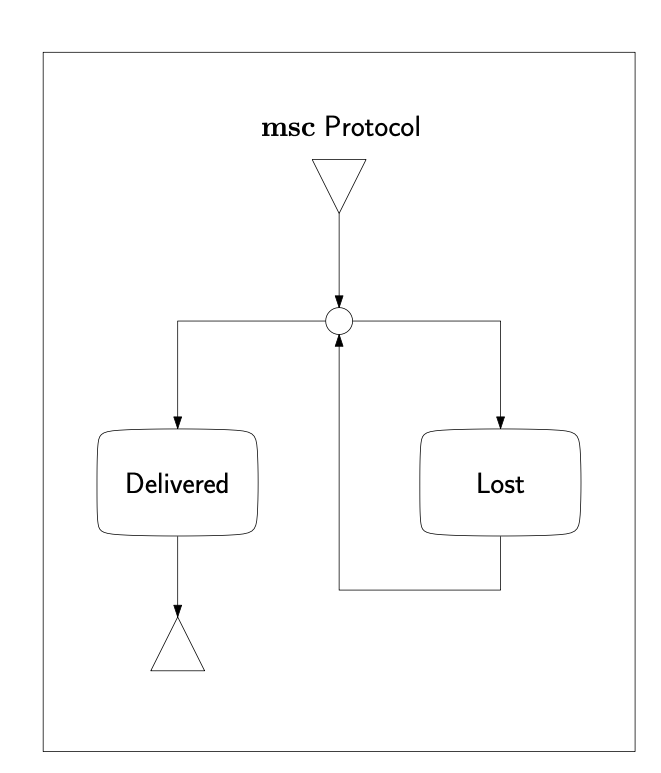
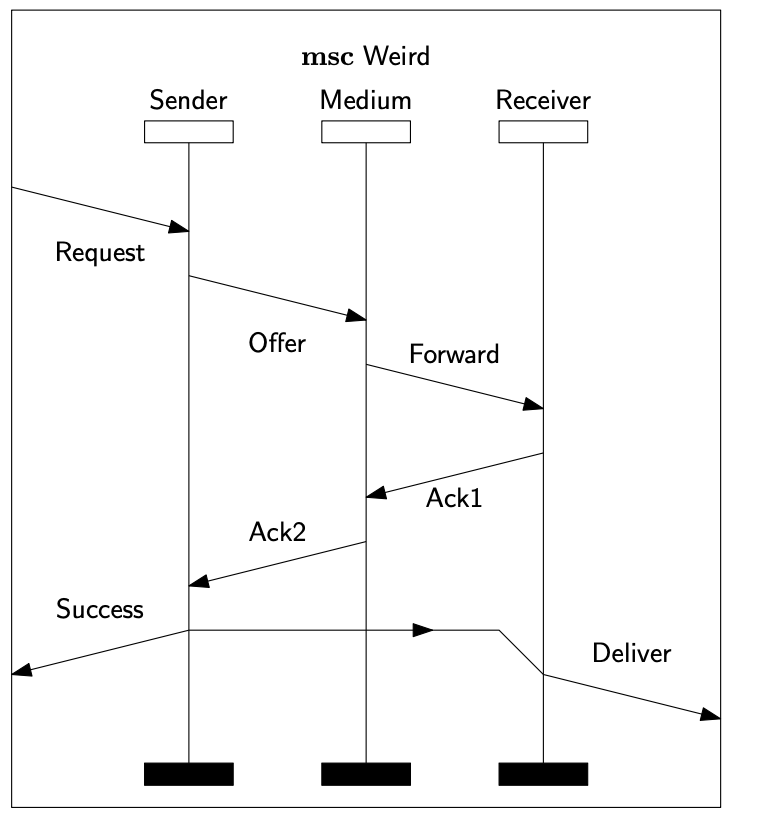
Package statistics
The website contains 85 items from the original package, including 59 Word files and 15 other files, plus the supplied paper PDF.
Raw data ZIP
The raw data archive is linked separately so that it can be uploaded alongside this website without increasing the website package size. Place the file at OneDrive_2026-05-11.zip to activate the link below.
Generation statement
This website was generated using GPT from the supplied paper PDF and source ZIP archive. The generation request was:
Hi, please generate a website as a replication package for the experiments reported in attached paper (attached as a pdf). Please include all the data and link to all the folders included in the attached .zip file; please reformat the Word files into html files with a uniform formatting. Please make sure that the contents are not modified. In the landing page, please include a brief overview of the problem statement and the experiments performed and link to the folders detailing the various steps. Please make sure that the pages all use consistent British English spelling. Please try to use the style of King's College London in terms of fonts and colours. Please produce a .zip file containing the website.